텍스트로 구성된 문서를 작은 조각(chunk)으로 나누는 chunking(청킹)을 하는 이유와 방법을 다루고, 청킹을 통해 얻은 문서 조각들이 RAG 파이프라인에서 어떻게 벡터로 변환·저장·검색되어 LLM의 답변 재료가 되는지까지의 전체 흐름을 설명하고 있습니다.
.
클로드 도움을 받아 작성되었습니다.
.
최초작성 2026. 3. 2
.
.

.
.
Chunking (청킹) 개념부터 실전까지
1. 개념 — Chunking이 뭔가요?
Chunking은 긴 텍스트 문서를 작은 텍스트 조각(chunk)으로 분할하는 과정입니다.
예를 들어 100페이지 문서를 여러 개의 텍스트 조각으로 분할하는 것입니다. 이 작업을 Chunking(청킹)이라고 부릅니다.
.
청킹에는 다음 두 가지 핵심 파라미터가 있습니다:
| 파라미터 | 의미 | 비유 |
| chunk_size | 한 조각의 최대 크기 (글자 수 또는 토큰 수) | 한 페이지에 적을 수 있는 최대 글자 수 |
| chunk_overlap | 인접한 조각끼리 겹치는 부분의 크기 | 앞 페이지 마지막 몇 줄을 다음 페이지 첫 줄에 다시 적는 것 |
토큰(token)이란? AI가 텍스트를 처리하는 최소 단위입니다. 영어에서는 대략 단어 하나가 1토큰이고, 한국어에서는 한 글자~한 단어가 1~3토큰 정도입니다. “안녕하세요”는 약 3~4토큰입니다. chunk_size를 글자 수 대신 토큰 수로 지정할 수도 있는데, LLM의 입력 제한(context window)이 토큰 단위이므로 토큰 기준이 LLM과 맞추기 더 쉽습니다.
.
.
2. 필요성 — 왜 Chunking을 해야 하나요?
문제 상황
LLM(대규모 언어 모델)에는 한 번에 처리할 수 있는 텍스트 양에 제한이 있습니다. 이 제한을 context window(컨텍스트 윈도우)라고 부르는데, 쉽게 말해 “AI가 한 번에 읽을 수 있는 텍스트 크기”라고 생각하면 됩니다.
또한 RAG(Retrieval-Augmented Generation, 검색 증강 생성)이라는 기술이 있습니다. 이것은 “AI에게 질문할때 먼저 관련 문서를 검색해서 참고 자료로 LLM에게 질문과 같이 제공하는 방식”입니다. 마치 오픈북 시험처럼, AI가 자기 기억에만 의존하지 않고 실제 문서를 보면서 답변하게 하는 것이죠. RAG에서는 질문과 관련된 부분만 정확히 찾아서 AI에게 건네줘야 하는데, 이때 Chunking이 핵심 역할을 합니다.
.
RAG에 대해서는 다음 블로그 글을 참고하세요.
RAG(Retrieval-Augmented Generation) 개념 및 구현
https://webnautes.com/%EC%A0%80%EC%9E%A5%EC%86%8C/136
.
Chunking이 필요한 3가지 이유
① LLM의 입력 제한
GPT-4의 context window = 약 128K 토큰
하지만 1,000페이지짜리 법률 문서 = 약 50만~100만 토큰
→ context window를 훨씬 초과하므로 한 번에 넣을 수 없다!
.
② 검색 정확도 향상
사용자 질문: “환불 정책이 뭐야?”
❌ 문서를 통째로 저장하면
→ 문서 전체가 반환됨 → 환불과 관련 없는 내용이 대부분. 환불 관련 있는 내용만 있어야 LLM 답변이 좋아진다.
.
✅ Chunk 단위로 쪼개서 저장하면
→ “환불 정책” chunk만 정확히 찾아서 반환
.
③ 비용 절감
LLM API는 토큰 수에 따라 비용이 발생합니다. 필요한 chunk만 보내면 비용을 크게 줄일 수 있습니다.
.
3. 원리 — 어떻게 동작하나요?
기본 동작 흐름
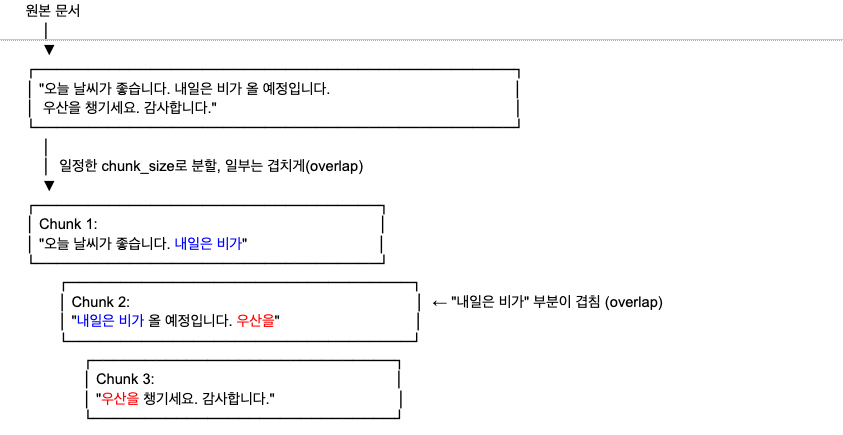
위 예시에서 Chunk 1의 끝 “내일은 비가”와 Chunk 2의 시작 “내일은 비가”가 동일합니다. 이것이 바로 overlap — 앞 chunk의 끝부분을 다음 chunk 시작에 다시 포함시키는 것입니다.
.
overlap이 왜 필요할까?
overlap이 없으면 문맥이 끊기는 문제가 발생합니다.
.

.
4. 종류 — Chunking 방법들
아래 4가지 방법을 모두 같은 원본 텍스트로 비교합니다.
원본 텍스트 (chunk_size = 30자로 가정):
“오늘 날씨가 좋습니다. 내일은 비가 올 예정입니다. 우산을 챙기세요. 주말에는 맑겠습니다.”
.
① 고정 크기 분할 (Fixed-size Chunking)
원리: 문장이든 단어든 상관없이, 정해진 글자 수마다 기계적으로 잘라냅니다. 마치 자(ruler)를 대고 일정 간격으로 가위질하는 것과 같습니다.
동작 방식: 처음부터 30자를 세어 자르고 → 다음 30자를 세어 자르고 → 끝까지 반복
.

.
⚠️ 문제: “비가 올” / ” 예정입니다” — 한 문장이 두 chunk에 찢어짐!
.
- 장점: 구현이 가장 간단하고 빠르다
- 단점: 문장 중간에서 잘려 의미가 깨질 수 있다
.
② 문장 기반 분할 (Sentence-based Chunking)
원리: 먼저 문장 단위(마침표, 물음표, 느낌표)로 텍스트를 분리한 뒤, chunk_size를 넘지 않는 범위에서 문장들을 하나의 chunk에 묶습니다. 문장을 쪼개지 않기 때문에 의미가 깨지지 않습니다.
동작 방식: 문장을 하나씩 chunk에 담으면서 → 다음 문장을 추가하면 30자를 넘기는 시점에서 → 현재까지를 하나의 chunk로 확정하고 → 새 chunk 시작
.
문장 분리 결과:
ⓐ “오늘 날씨가 좋습니다.” (12자)
ⓑ “내일은 비가 올 예정입니다.” (15자)
ⓒ “우산을 챙기세요.” (9자)
ⓓ “주말에는 맑겠습니다.” (11자)
.
Chunk 구성 과정:
ⓐ(12자) + ⓑ(15자) = 27자 ← 30자 이내이므로 계속 담기
27자 + ⓒ(9자) = 36자 ← 30자 초과! → 여기서 chunk 확정
.
Chunk 1: “오늘 날씨가 좋습니다. 내일은 비가 올 예정입니다.” (27자)
Chunk 2: “우산을 챙기세요. 주말에는 맑겠습니다.” (20자)
.
✅ 모든 문장이 온전하게 보존됨!
.
- 장점: 문장이 중간에 잘리지 않아 의미가 보존된다
- 단점: chunk마다 크기가 들쭉날쭉할 수 있다 (위 예시: 27자 vs 20자)
.
③ 재귀적 분할 (Recursive Chunking)
원리: 구분자에 우선순위를 두고, 큰 단위부터 먼저 자릅니다. 잘린 조각이 아직 chunk_size보다 크면 그 다음 순위의 구분자로 다시 자르고, 그래도 크면 또 다시 자르는 과정을 반복합니다. “재귀적”이라는 이름은 이 반복 적용에서 나왔습니다.
LangChain(랭체인)에서 가장 많이 쓰이는 방식이기도 합니다. (LangChain은 LLM 기반 앱을 만들 때 널리 쓰이는 Python 라이브러리입니다.)
.
구분자 우선순위:
1순위: 문단 구분 (\n\n) — 가장 큰 의미 단위
2순위: 줄바꿈 (\n) — 문단보다 작은 단위
3순위: 문장 끝 (. ) — 문장 단위
4순위: 공백 ( ) — 단어 단위
5순위: 글자 하나씩 (“”) — 최후의 수단
.
동작 예시 (chunk_size = 80자로 가정):

.
━━━ 1단계: 1순위 구분자(\n\n = 문단)로 분할 ━━━
조각 A: “제1조 (연차휴가)\n모든 정규직 직원은…” (52자) ← 80자 이내 완성
조각 B: “제2조 (병가)\n질병으로…제출해야 한다.” (75자) ← 80자 이내 완성
.
→ 두 조각 모두 80자 이내이므로 여기서 끝!
.
.
━━━ 만약 조각 B가 80자를 넘었다면? ━━━
2단계: 조각 B를 2순위 구분자(\n = 줄바꿈)로 다시 분할
→ “제2조 (병가)\n질병으로…” 와 “3일 이상 병가 시…”
.
그래도 넘으면 → 3순위(문장)로 또 분할
그래도 넘으면 → 4순위(단어)로 또 분할
…이 반복이 “재귀적”인 이유!
.
- 장점: 큰 의미 단위(문단)를 최대한 유지하면서, 필요할 때만 더 잘게 나눈다
- 단점: 구분자 우선순위 등 설정할 것이 많다
.
④ 의미 기반 분할 (Semantic Chunking)
원리: 위 3가지 방법은 모두 글자 수나 구두점 같은 형식을 기준으로 자릅니다. 의미 기반 분할은 다릅니다 — 텍스트의 의미(주제)가 크게 바뀌는 지점을 찾아서 거기서 자릅니다.
구체적인 과정은: 각 문장을 임베딩 모델로 숫자 배열(벡터)로 변환한 뒤, 인접한 문장의 벡터를 비교합니다. 벡터가 비슷하면 “같은 주제”, 벡터가 갑자기 크게 달라지면 “여기서 주제가 바뀌었다!”로 판단하여 그 지점에서 자릅니다.
.
동작 예시:
원본 문장들과 주제:
ⓐ “올해 매출은 전년 대비 20% 증가했다.” ← 매출 주제
ⓑ “특히 해외 시장에서의 성장이 두드러졌다.” ← 매출 주제
ⓒ “신규 채용은 50명을 목표로 하고 있다.” ← 채용 주제 ⬅ 주제 전환!
ⓓ “기술직 엔지니어 30명을 우선 채용할 예정이다.” ← 채용 주제
.
각 문장의 벡터 비교:
ⓐ↔ⓑ 유사도: 0.92 (매출↔매출 = 같은 주제 → 자르지 않음)
ⓑ↔ⓒ 유사도: 0.31 (매출↔채용 = 주제 전환! → 여기서 자름!)
ⓒ↔ⓓ 유사도: 0.89 (채용↔채용 = 같은 주제 → 자르지 않음)
.
결과:
Chunk 1: “올해 매출은 전년 대비 20% 증가했다.
특히 해외 시장에서의 성장이 두드러졌다.” ← 매출 chunk
Chunk 2: “신규 채용은 50명을 목표로 하고 있다.
기술직 엔지니어 30명을 우선 채용할 예정이다.” ← 채용 chunk
주제별로 자연스럽게 분리됨!
.
- 장점: 의미적으로 가장 자연스러운 분할 (주제가 섞이지 않음)
- 단점: 임베딩 모델을 호출해야 하므로 비용이 발생하고 속도가 느림
.
재귀적 분할이 가장 많이 쓰입니다. 구현이 크게 어렵지 않으면서도 문맥 보존이 좋고, 추가 비용이 없기 때문입니다. 의미 기반 분할은 정확도가 중요한 프로젝트에서 선택적으로 사용합니다.
.
.
5. 실전 예제
예제: 문서를 chunk로 분할하고 유사도 검색하기
.
예제를 실행하려면 다음 패키지를 설치해야 합니다.
pip install langchain langchain-community chromadb langchain-text-splitters langchain-huggingface sentence-transformers
.
.
| import warnings warnings.filterwarnings(“ignore”) from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.vectorstores import Chroma from langchain_huggingface import HuggingFaceEmbeddings # ── Step 1: 원본 문서 준비 ── document = “”” 회사 내규 – 휴가 정책 제1조 (연차휴가) 모든 정규직 직원은 입사 1년 후부터 연간 15일의 유급 연차휴가를 사용할 수 있다. 입사 3년차부터는 2년마다 1일씩 추가되며, 최대 25일까지 부여된다. 제2조 (병가) 질병이나 부상으로 인한 병가는 연간 최대 30일까지 사용 가능하다. 3일 이상 연속 병가 시 의사 진단서를 제출해야 한다. 제3조 (경조사 휴가) 본인 결혼: 5일, 자녀 결혼: 1일, 배우자 출산: 10일, 부모 사망: 5일, 형제자매 사망: 3일의 경조사 휴가가 부여된다. 제4조 (휴가 신청) 휴가는 최소 3일 전에 직속 상사에게 신청해야 하며, 긴급한 경우 당일 신청도 가능하나 사후 승인을 받아야 한다. “”” # ── Step 2: Chunking ── splitter = RecursiveCharacterTextSplitter( chunk_size=150, chunk_overlap=30, separators=[“\n\n”, “\n”, ” “, “”] ) chunks = splitter.split_text(document) for i, chunk in enumerate(chunks): print(f”— Chunk {i+1} (길이: {len(chunk)}자) —“) print(chunk) print() # ── Step 3: 벡터 DB에 저장 ── embedding = HuggingFaceEmbeddings(model_name=”jhgan/ko-sbert-multitask”) vectorstore = Chroma.from_texts(texts=chunks, embedding=embedding) # ── Step 4: 질문으로 관련 chunk 검색 ── query = “경조사 휴가는 며칠이야?” results = vectorstore.similarity_search(query, k=1) print(f”🔍 질문: {query}”) print(“검색 결과:”) for doc in results: print(doc.page_content) |
.
.
실행하면 문서 조각들을 보여주고 질문에 대한 검색 결과를 보여줍니다. 경조사 휴가를 물어보는 질문에 관련 문서 조각인 3조항을 보여주고 있습니다.
HF_TOKEN를 설정하면 실행결과에 보이는 경고는 사라집니다.
| — Chunk 1 (길이: 113자) — 회사 내규 – 휴가 정책 제1조 (연차휴가) 모든 정규직 직원은 입사 1년 후부터 연간 15일의 유급 연차휴가를 사용할 수 있다. 입사 3년차부터는 2년마다 1일씩 추가되며, 최대 25일까지 부여된다. — Chunk 2 (길이: 77자) — 제2조 (병가) 질병이나 부상으로 인한 병가는 연간 최대 30일까지 사용 가능하다. 3일 이상 연속 병가 시 의사 진단서를 제출해야 한다. — Chunk 3 (길이: 85자) — 제3조 (경조사 휴가) 본인 결혼: 5일, 자녀 결혼: 1일, 배우자 출산: 10일, 부모 사망: 5일, 형제자매 사망: 3일의 경조사 휴가가 부여된다. — Chunk 4 (길이: 75자) — 제4조 (휴가 신청) 휴가는 최소 3일 전에 직속 상사에게 신청해야 하며, 긴급한 경우 당일 신청도 가능하나 사후 승인을 받아야 한다. Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads. Loading weights: 100%|███████████████████████████████████████████████████████████████████| 199/199 [00:00<00:00, 6696.51it/s, Materializing param=pooler.dense.weight] BertModel LOAD REPORT from: jhgan/ko-sbert-multitask Key | Status | | ————————+————+–+- embeddings.position_ids | UNEXPECTED | | Notes: – UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch. 🔍 질문: 경조사 휴가는 며칠이야? 검색 결과: 제3조 (경조사 휴가) 본인 결혼: 5일, 자녀 결혼: 1일, 배우자 출산: 10일, 부모 사망: 5일, 형제자매 사망: 3일의 경조사 휴가가 부여된다. |
.
.
6. RAG 파이프라인에서 Chunking은 어떻게 쓰일까?
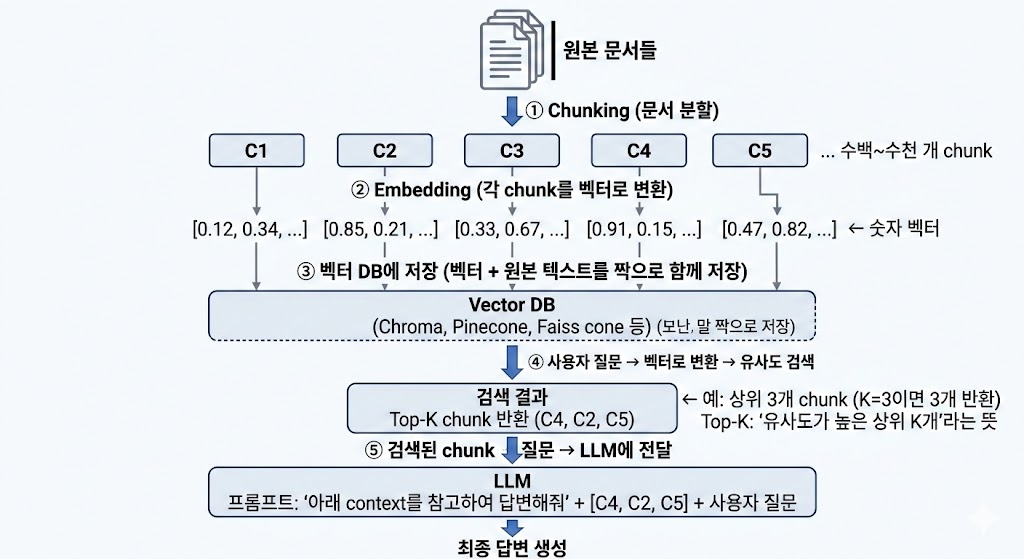
RAG(Retrieval-Augmented Generation)는 크게 사전 준비와 질의 응답 두 단계로 나뉩니다.
- 사전 준비: 문서를 chunk로 분할(①) → 각 chunk를 벡터로 변환(②) → 벡터 DB에 저장(③)
- 질의 응답: 질문과 비슷한 chunk를 벡터로 검색(④) → LLM에 전달하여 답변 생성(⑤)
.
질의 응답 단계(④~⑤)를 좀 더 자세히 풀어보면 Stage 1(벡터 검색) → Stage 2(원본 텍스트 복원) → Stage 3(LLM 전달)의 3단계로 나눌 수 있습니다. 각 Stage를 하나씩 살펴보겠습니다.
.
임베딩(Embedding)과 벡터(Vector)란?
이 섹션에서 계속 나오는 핵심 개념이므로 먼저 알고 가겠습니다.
벡터(Vector) = 숫자들의 나열입니다. 예를 들어 [0.12, 0.34, 0.56]처럼 생겼습니다.
임베딩(Embedding) = 텍스트의 “의미”를 벡터(숫자 배열)로 변환하는 과정입니다.
왜 이런 걸 할까요? 컴퓨터는 “경조사 휴가”와 “결혼 축하 쉬는 날”이 비슷한 의미라는 걸 글자만 봐서는 알 수 없습니다. 하지만 둘 다 벡터로 바꾸면, 숫자끼리 비교해서 “이 둘은 비슷한 의미구나!”라고 판단할 수 있습니다.
.
“경조사 휴가” → [0.33, 0.67, 0.89, …]
“결혼 축하 쉬는 날” → [0.31, 0.65, 0.87, …] ← 숫자가 비슷함 = 의미가 비슷!
“서버 장애 보고서” → [0.91, 0.12, 0.05, …] ← 숫자가 다름 = 의미가 다름!
.
전체 흐름 한눈에 보기
.
.
.
Stage 1: 검색 단계 — chunk가 “검색 단위”가 된다
벡터 DB에는 chunk 하나당 하나의 행이 저장됩니다. (각 행에는 벡터 + 원본 텍스트 + 메타데이터가 들어있는데, 이 구조는 Stage 2에서 자세히 설명합니다.)
사용자 질문이 들어오면, 질문도 벡터로 바꾼 뒤 DB의 벡터들과 비교하여 가장 의미가 비슷한 chunk를 찾아냅니다.
.
여기서 chunk_size가 중요한 이유:

.
.
Stage 2: 검색된 벡터에서 원본 텍스트를 돌려받는 원리
여기서 헷갈리는 부분이 있습니다.
“벡터(숫자 배열)에서 어떻게 다시 원래 텍스트로 돌아가지?”
.
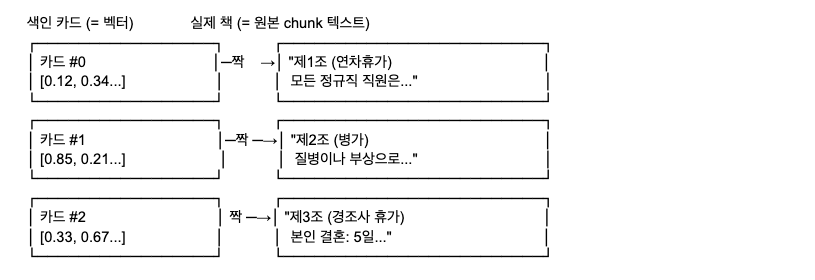
정답은: 돌아가는 게 아닙니다! 벡터를 역변환하는 것이 아니라, 처음부터 원본 텍스트와 벡터를 짝으로 묶어서 저장해 둔 것입니다.
.
핵심 원리: 도서관의 색인 카드 시스템
.
.
벡터로 변환한 질문과 유사한 벡터를 찾은 후, 짝으로 묶여있는 텍스트를 찾습니다.
.
벡터 DB 내부에 실제로 저장되는 것
벡터 DB는 단순히 벡터만 저장하는 게 아닙니다. 각 항목마다 3가지를 한 묶음으로 저장합니다.
메타데이터(metadata)란? “데이터에 대한 데이터”라는 뜻입니다. chunk 원문이 “본체 데이터”라면, “이 chunk가 어떤 파일의 몇 페이지에서 왔는지” 같은 부가 정보가 메타데이터입니다. 사진 파일에 촬영 날짜, 위치 정보가 붙어 있는 것과 같은 개념입니다.
.
벡터 DB 내부 구조 (한 행 = 한 chunk)
| ID | 벡터 (검색용 인덱스) | 원본 텍스트 + 메타데이터 (검색 후 LLM에 전달할 내용) |
| 0 | [0.12, 0.34, 0.56, 0.78, 0.91, …] | text: “제1조 (연차휴가) 모든…”meta: {파일: “내규.pdf”, 페이지:1} |
| 1 | [0.85, 0.21, 0.43, 0.67, 0.12, …] | text: “제2조 (병가) 질병이나…” meta: {파일: “내규.pdf”, 페이지:1} |
| 2 | [0.33, 0.67, 0.89,0.14, 0.55, …] | text: “제3조 (경조사) 본인…” meta: {파일: “내규.pdf”, 페이지:2} |
벡터 열 → 임베딩 모델이 chunk 텍스트를 변환한 숫자 배열. 검색할 때만 사용됨.
(사람이 읽을 수 있는 텍스트가 아님 — 오직 비교용)
.
텍스트 열 → chunk의 원문 그대로. 검색 후 이것이 LLM에 참고 자료로 전달됨.
.
메타데이터 열 → 이 chunk가 어떤 파일의 몇 페이지에서 왔는지 출처 정보.
.
.
Stage 3: LLM 전달 단계 — chunk 텍스트를 프롬프트에 삽입
Stage 2에서 꺼낸 원본 텍스트 조각들을 하나의 프롬프트 안에 “참고 자료”로 넣어서 LLM에 보냅니다.
이 과정은 의외로 단순합니다. 검색된 chunk의 원본 텍스트들을 이어 붙이고, “이 자료를 참고해서 답변해줘”라는 지시문과 사용자 질문을 합쳐서 하나의 문자열로 만드는 것이 전부입니다.
.
.
여기서 메타데이터의 역할이 빛을 발합니다. 출처 정보를 함께 넣어주면 LLM이 “이 내용은 회사내규.pdf 2페이지에 근거합니다”처럼 출처를 밝히는 답변을 생성할 수 있습니다.
.
검색 단위 vs 전달 단위를 다르게 쓰는 고급 기법
Stage 1~3을 보면 한 가지 딜레마가 보입니다.
chunk가 작으면 → 검색은 정확한데, LLM에 전달되는 문맥이 부족
chunk가 크면 → 문맥은 충분한데, 검색 정확도가 떨어짐
.
이 문제를 해결하기 위해 검색용 chunk와 LLM 전달용 chunk를 다르게 설정합니다.
.
Parent-Child Chunking (Small-to-Big 전략)
RAG(Retrieval-Augmented Generation)에서 자주 쓰이는 청킹 전략인데, 핵심 아이디어는 간단합니다.
검색은 작은 덩어리로, 응답 생성은 큰 덩어리로 하는 것입니다.
.
왜 필요한가?
청킹에는 근본적인 딜레마가 있습니다.
덩어리가 크면 문맥은 풍부하지만, 검색 정확도가 떨어집니다. 관련 없는 내용이 섞여 임베딩 벡터가 희석되기 때문입니다.
덩어리가 작으면 검색 정확도는 높지만, LLM에 전달할 문맥이 부족합니다. 답변을 생성하기에 정보가 너무 적은 거죠.
Parent-Child Chunking은 이 두 가지 장점을 동시에 취하려는 전략입니다.
.
어떻게 동작하나?
비유하자면 책의 목차와 본문의 관계와 비슷합니다.
- Parent Chunk (부모) — 문서를 큰 단위로 나눕니다. 예를 들어 500토큰 단위. 이것이 “큰 문맥 덩어리”입니다.
- Child Chunk (자식) — 각 부모 청크를 다시 작은 단위로 쪼갭니다. 예를 들어 100토큰 단위. 이것이 “검색용 덩어리”입니다. 각 자식은 자신이 어떤 부모에 속하는지 참조(링크)를 갖고 있습니다.
- 검색 시 — 사용자 질문과 자식 청크들을 비교해서 가장 관련 높은 자식을 찾습니다. 작은 덩어리라 임베딩이 정밀하므로 검색 정확도가 높습니다.
- 응답 생성 시 — 찾은 자식 청크 대신, 그 자식이 속한 부모 청크를 LLM에 전달합니다. 덕분에 LLM은 충분한 문맥을 가지고 답변을 생성할 수 있습니다.
.
예시
원본 문서 한 단락(Parent)이 이렇다고 해봅시다:
“파이썬은 1991년 귀도 반 로섬이 만들었다. 간결한 문법이 특징이며, 데이터 과학과 웹 개발에 널리 쓰인다. 최근에는 AI/ML 분야에서 사실상 표준 언어가 되었다.”
이걸 Child로 쪼개면:
- Child 1: “파이썬은 1991년 귀도 반 로섬이 만들었다.”
- Child 2: “간결한 문법이 특징이며, 데이터 과학과 웹 개발에 널리 쓰인다.”
- Child 3: “최근에는 AI/ML 분야에서 사실상 표준 언어가 되었다.”
사용자가 “파이썬 만든 사람이 누구야?”라고 물으면 → Child 1이 정확히 매칭됩니다. 하지만 LLM에는 전체 Parent를 넘겨서 풍부한 문맥으로 답변하게 합니다.
.
“Small-to-Big”이라는 이름이 붙은 이유가 바로 이것입니다. 작은 것으로 찾고, 큰 것으로 답한다는 거죠.
.
.
RAG에서 각 단계별 Chunk의 역할
RAG 파이프라인은 크게 4단계로 나뉘는데, 각 단계에서 chunk가 하는 일과 chunk 크기의 영향이 다릅니다.
.
1단계: 저장
chunk는 벡터 DB에 저장되는 기본 단위입니다. 하나의 chunk마다 “임베딩 벡터 + 원본 텍스트”가 한 쌍으로 저장됩니다. chunk 크기가 크면 전체 chunk 수가 줄어들고, 작으면 chunk 수가 늘어납니다.
2단계: 검색 (Stage 1)
chunk는 유사도 비교의 기본 단위입니다. 사용자의 질문을 벡터로 변환한 뒤, 저장된 각 chunk의 벡터와 비교해서 가장 유사한 것을 찾습니다. chunk가 크면 관련 없는 내용이 섞여 검색 정확도가 떨어지고, 작으면 의미가 집중되어 정확도가 올라갑니다.
3단계: 복원 (Stage 2)
검색에서 찾은 벡터의 짝인 원본 텍스트를 그대로 꺼내는 단계입니다. 여기서 중요한 점은, 벡터를 역변환해서 텍스트를 만드는 게 아니라는 것입니다. 애초에 저장해둔 원본 텍스트를 그대로 반환하는 것뿐입니다.
4단계: LLM 전달 (Stage 3)
복원된 텍스트가 프롬프트의 context(참고 자료)로 삽입됩니다. chunk가 크면 LLM이 참고할 문맥이 풍부해지지만 토큰 비용이 늘고, 작으면 비용은 줄지만 문맥이 부족해질 수 있습니다.
.
핵심 딜레마
결국 검색 정확도(작은 chunk가 유리)와 LLM 문맥의 풍부함(큰 chunk가 유리) 사이에서 균형을 잡아야 합니다. 이 딜레마를 해결하는 대표적인 방법이 바로 앞서 이야기한 Parent-Child 전략입니다. 검색은 작은 chunk로 정밀하게 하고, LLM에는 그 부모인 큰 chunk를 넘겨서 두 마리 토끼를 동시에 잡는 것이죠.
7. chunk_size와 overlap 설정 팁
chunk_size 가이드
.
100~300자 → 짧은 Q&A, FAQ 문서
300~500자 → 일반적인 문서 (가장 많이 사용)
500~1000자 → 기술 문서, 긴 문맥이 필요한 경우
1000자 이상 → 법률 문서, 논문 등 전문 문서
.
.
overlap 가이드
일반적으로 chunk_size의 10~20%가 적당
예: chunk_size=500 → overlap=50~100
.
핵심 원칙: chunk가 너무 작으면 문맥이 부족하고, 너무 크면 검색 정확도가 떨어집니다. 프로젝트에 맞게 실험하며 조절하세요!
.
.